Chatbot mới của Deepseek đã tạo nên làn sóng trong ngành công nghiệp AI, định vị mình là đối thủ cạnh tranh đáng gờm. Công ty đã giới thiệu AI của mình với khẩu hiệu hấp dẫn: "Xin chào, tôi đã được tạo ra để bạn có thể hỏi bất cứ điều gì và nhận được câu trả lời thậm chí có thể làm bạn ngạc nhiên." Tuyên bố táo bạo này đã cộng hưởng với người dùng, và ngày nay, những tiến bộ của Deepseek đã góp phần vào một trong những khoản giảm giá cổ phiếu lớn nhất đối với NVIDIA, nêu bật tác động của công nghệ.
 Hình ảnh: Ensigame.com
Hình ảnh: Ensigame.com
Điều làm cho mô hình của Deepseek khác biệt là kiến trúc và phương pháp đào tạo sáng tạo của nó. Dưới đây là các công nghệ chính cung cấp năng lượng cho AI của nó:
Dự đoán đa điểm (MTP): Không giống như các mô hình truyền thống dự đoán một từ tại một thời điểm, phương pháp MTP của Deepseek dự đoán đồng thời nhiều từ bằng cách phân tích các phần khác nhau của một câu. Phương pháp này tăng cường cả độ chính xác và hiệu quả của mô hình.
Hỗn hợp các chuyên gia (MOE): Kiến trúc này sử dụng các mạng thần kinh khác nhau để xử lý dữ liệu đầu vào. Nó tăng tốc đào tạo AI và cải thiện hiệu suất. Trong DeepSeek V3, 256 mạng thần kinh được sử dụng, với tám mạng được kích hoạt cho mỗi nhiệm vụ xử lý mã thông báo.
Sự chú ý tiềm ẩn đa đầu (MLA): Cơ chế này tập trung vào các phần quan trọng nhất của một câu. MLA trích xuất các chi tiết chính từ các đoạn văn bản nhiều lần, giảm khả năng thiếu thông tin quan trọng. Điều này đảm bảo AI nắm bắt các sắc thái quan trọng trong dữ liệu đầu vào.
 Hình ảnh: Ensigame.com
Hình ảnh: Ensigame.com
Deepseek, một công ty khởi nghiệp nổi tiếng của Trung Quốc, tuyên bố đã phát triển một mô hình AI cạnh tranh với chi phí tối thiểu, nói rằng họ chỉ chi 6 triệu đô la cho việc đào tạo mạng lưới thần kinh mạnh mẽ Deepseek V3 và chỉ sử dụng 2048 bộ xử lý đồ họa. Tuy nhiên, các nhà phân tích từ Semianalysis đã tiết lộ rằng Deepseek vận hành một cơ sở hạ tầng tính toán rộng lớn bao gồm khoảng 50.000 GPU phễu NVIDIA, bao gồm 10.000 đơn vị H800, 10.000 H100 cao hơn và GPU H20 bổ sung. Các tài nguyên này được phân phối trên một số trung tâm dữ liệu và được sử dụng để đào tạo, nghiên cứu và mô hình tài chính của AI.
Tổng đầu tư của công ty vào máy chủ lên tới khoảng 1,6 tỷ đô la, với chi phí hoạt động ước tính là 944 triệu đô la. Deepseek là một công ty con của FLEGER FLEGER của Quỹ phòng hộ Trung Quốc, giúp khởi động như một bộ phận riêng biệt tập trung vào AI Technologies vào năm 2023. Không giống như hầu hết các công ty khởi nghiệp cho thuê sức mạnh điện toán từ các nhà cung cấp đám mây, DeepSeek sở hữu các trung tâm dữ liệu riêng của mình, giúp nó hoàn toàn kiểm soát tối ưu hóa mô hình AI. Công ty vẫn tự tài trợ, tác động tích cực đến tính linh hoạt và tốc độ ra quyết định của nó.
 Hình ảnh: Ensigame.com
Hình ảnh: Ensigame.com
Hơn nữa, một số nhà nghiên cứu tại Deepseek kiếm được hơn 1,3 triệu đô la hàng năm, thu hút tài năng hàng đầu từ các trường đại học hàng đầu Trung Quốc (công ty không thuê các chuyên gia nước ngoài). Ngay cả khi xem xét điều này, yêu cầu đào tạo gần đây của Deepseek về mô hình mới nhất của mình chỉ với 6 triệu đô la có vẻ không thực tế. Con số này chỉ đề cập đến chi phí sử dụng GPU trong quá trình đào tạo trước và không chiếm chi phí nghiên cứu, sàng lọc mô hình, xử lý dữ liệu hoặc chi phí cơ sở hạ tầng tổng thể.
Kể từ khi thành lập, Deepseek đã đầu tư hơn 500 triệu đô la vào phát triển AI. Tuy nhiên, không giống như các công ty lớn hơn bị gánh nặng bởi quan liêu, cấu trúc nhỏ gọn của Deepseek cho phép nó thực hiện tích cực và hiệu quả các đổi mới AI.
 Hình ảnh: Ensigame.com
Hình ảnh: Ensigame.com
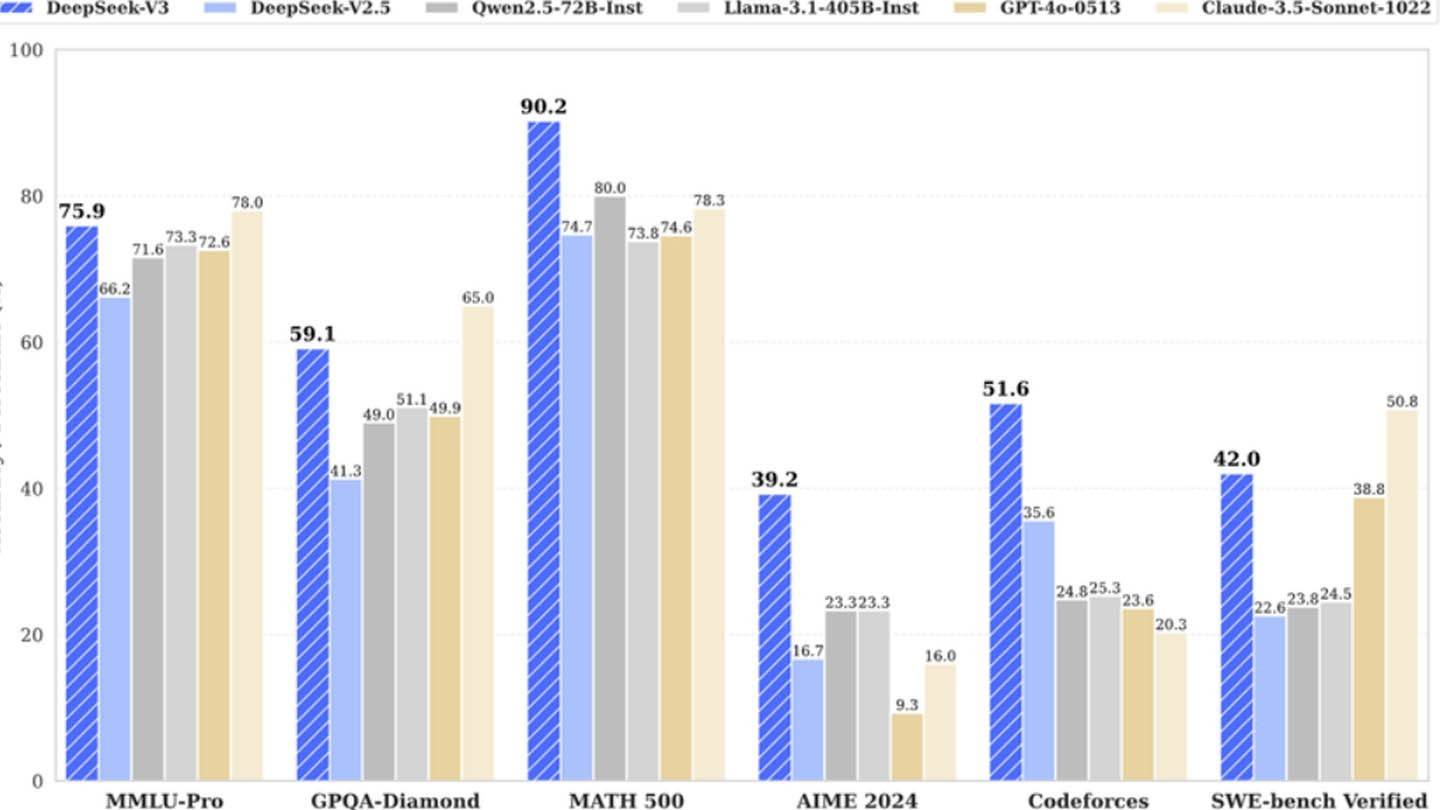
Ví dụ về DeepSeek chứng minh rằng một công ty AI độc lập được tài trợ tốt có thể cạnh tranh với các nhà lãnh đạo ngành công nghiệp. Tuy nhiên, các chuyên gia nhấn mạnh rằng thành công của công ty chủ yếu là do hàng tỷ khoản đầu tư, đột phá kỹ thuật và một nhóm mạnh mẽ, trong khi tuyên bố về "ngân sách cách mạng" để phát triển các mô hình AI có phần phóng đại. Tuy nhiên, chi phí của đối thủ vẫn cao hơn đáng kể. Chẳng hạn, so sánh chi phí đào tạo mô hình: Deepseek đã chi 5 triệu đô la cho R1, trong khi TATGPT4O có giá 100 triệu đô la.