Deepseekの新しいチャットボットは、AI業界で波を起こし、手ごわい競合他社としての地位を確立しています。同社は興味深いキャッチフレーズでAIを紹介しました:「こんにちは、私はあなたが何でも尋ねて、あなたを驚かせるかもしれない答えを得ることができるように作成されました。」この大胆な声明はユーザーと共鳴しており、今日、Deepseekの進歩はNVIDIAの最大の株価下落の1つに貢献し、そのテクノロジーの影響を強調しています。
 画像:Ensigame.com
画像:Ensigame.com
Deepseekのモデルを際立たせるのは、革新的なアーキテクチャとトレーニング方法です。これがAIを動かす重要なテクノロジーです。
マルチトークン予測(MTP):一度に1つの単語を予測する従来のモデルとは異なり、DeepSeekのMTPアプローチは、文のさまざまな部分を分析することにより、複数の単語を同時に予測します。この方法は、モデルの精度と効率の両方を向上させます。
専門家の混合(MOE):このアーキテクチャは、さまざまなニューラルネットワークを採用して入力データを処理します。 AIトレーニングを加速し、パフォーマンスを向上させます。 DeepSeek V3では、256のニューラルネットワークが利用され、トークン処理タスクごとに8つがアクティブ化されています。
マルチヘッド潜在的注意(MLA):このメカニズムは、文の最も重要な部分に焦点を当てています。 MLAは、テキストフラグメントから重要な詳細を繰り返し抽出し、重要な情報が欠落している可能性を減らします。これにより、AIが入力データの重要なニュアンスをキャプチャすることが保証されます。
 画像:Ensigame.com
画像:Ensigame.com
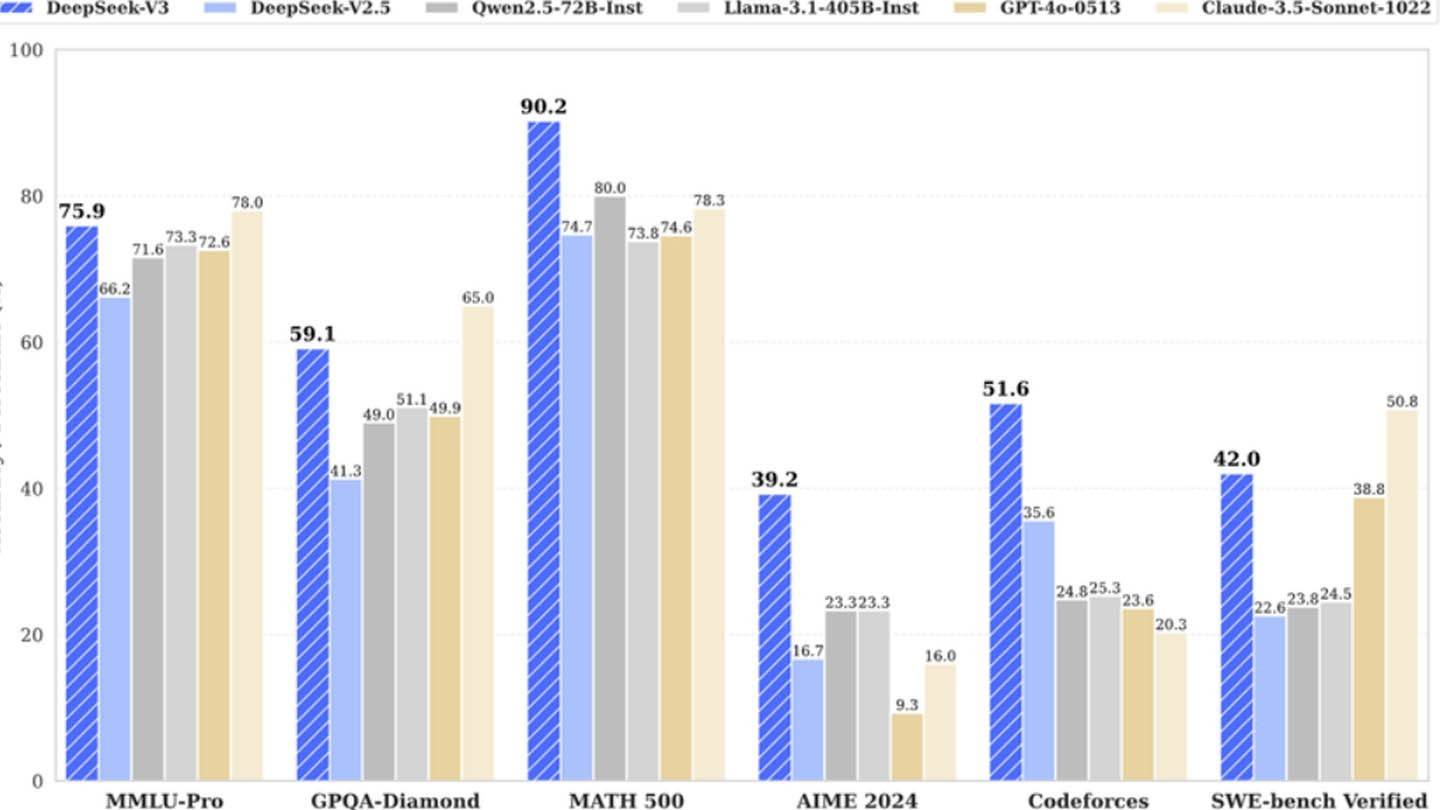
中国の著名なスタートアップであるDeepseekは、最小限のコストで競争力のあるAIモデルを開発したと主張しており、強力なニューラルネットワークDeepSeek V3のトレーニングにわずか600万ドルを費やし、2048グラフィックプロセッサのみを使用していると述べています。ただし、Semianalysisのアナリストは、DeepSeekが10,000 H800ユニット、10,000人の高度なH100、追加のH20 GPUを含む約50,000のNVIDIAホッパーGPUを含む膨大な計算インフラストラクチャを運営していることを明らかにしました。これらのリソースは、いくつかのデータセンターに配布されており、AIトレーニング、研究、財務モデリングに利用されています。
同社のサーバーへの総投資は約16億ドルに達し、運用費用は9億4,400万ドルと推定されています。 Deepseekは、中国のヘッジファンドの高級家の子会社であり、2023年にAIテクノロジーに焦点を当てた別の部門としてスタートアップを紡ぎました。クラウドプロバイダーからコンピューティングパワーをレンタルするほとんどのスタートアップとは異なり、DeepSeekはAIモデルの最適化を完全に制御し、イノベーションの高速化を可能にします。同社は自己資金のままであり、柔軟性と意思決定速度にプラスの影響を与えます。
 画像:Ensigame.com
画像:Ensigame.com
さらに、Deepseekの一部の研究者は、年間130万ドル以上を稼ぎ、中国の主要な大学から最高の才能を引き付けます(同社は外国人の専門家を雇いません)。これを考慮しても、わずか600万ドルで最新のモデルをトレーニングするというDeepseekの最近の主張は非現実的に思えます。この数字は、トレーニング前のGPU使用のコストのみを指し、研究費用、モデルの洗練、データ処理、または全体的なインフラストラクチャコストを考慮していません。
Deepseekは設立以来、AI開発に5億ドル以上を投資してきました。ただし、官僚機構に悩まされる大企業とは異なり、Deepseekのコンパクト構造により、AIイノベーションを積極的かつ効果的に実装することができます。
 画像:Ensigame.com
画像:Ensigame.com
Deepseekの例は、資金提供された独立したAI会社が業界のリーダーと競争できることを示しています。それにもかかわらず、専門家は、同社の成功は主に投資、技術的なブレークスルー、強力なチームの数十億のためであることを強調していますが、AIモデルの開発のための「革新的な予算」についての主張はやや誇張されています。それでも、競合他社のコストは依然として大幅に高くなっています。たとえば、モデルトレーニングのコストを比較してください:DeepseekはR1に500万ドルを費やしましたが、ChatGpt4oは1億ドルかかります。